One surface, 200+ data sources: how Anysite's five MCP tools stay flat as the catalog grows
If you have wired more than a couple of MCP servers into an agent, you have probably watched the context window fill up before the agent does anything useful. Every connected server ships its tools as a flat list, and every one of those definitions — names, descriptions, parameter schemas — gets loaded into the model's context on each turn. The data you actually want is still one tool call away, but a meaningful slice of the window is already gone.
This is not a hypothetical. In its November 2025 write-up on advanced tool use, Anthropic noted that "tool results and definitions can sometimes consume 50,000+ tokens before an agent reads a request." It walked through a five-server setup that put 58 tools and roughly 55K tokens into context before the conversation even started; add a server like Jira, which alone runs about 17K tokens, and you are approaching a 100K-token overhead. Anthropic also reported that its own internal stack hit 134K tokens of tool definitions before it was optimized.
Two things degrade as that list grows. The obvious one is token cost: context spent on definitions is context unavailable for reasoning, retrieved data, and conversation history. The less obvious one is selection accuracy. When a model has to pick the right tool from hundreds of near-duplicate options — twelve different "search" endpoints across twelve sources — it picks wrong more often. More tools is not strictly more capability; past a point it is more ways to misfire.
The flat list is the default, not a law
The MCP specification gives a server one primary way to advertise what it can do: tools/list. A client reads that list and hands it to the model. For a server with five or ten tools, that is fine. For a data-extraction platform that covers dozens of sources — each with profile lookups, search, pagination, and detail endpoints — a one-tool-per-endpoint mapping turns into hundreds of definitions. The interface scales linearly with the catalog, and the model pays for the whole catalog whether it touches one source or twenty.
The industry is converging on the same fix from several directions. Anthropic's Tool Search Tool is the clearest example: instead of loading every definition upfront, the model is given a search tool and discovers the three to five tools it actually needs on demand. Anthropic measured this preserving 191,300 tokens of context against 122,800 with the traditional load-everything approach. The shared idea across these efforts is simple — move tool access out of the context window and into a discovery step.
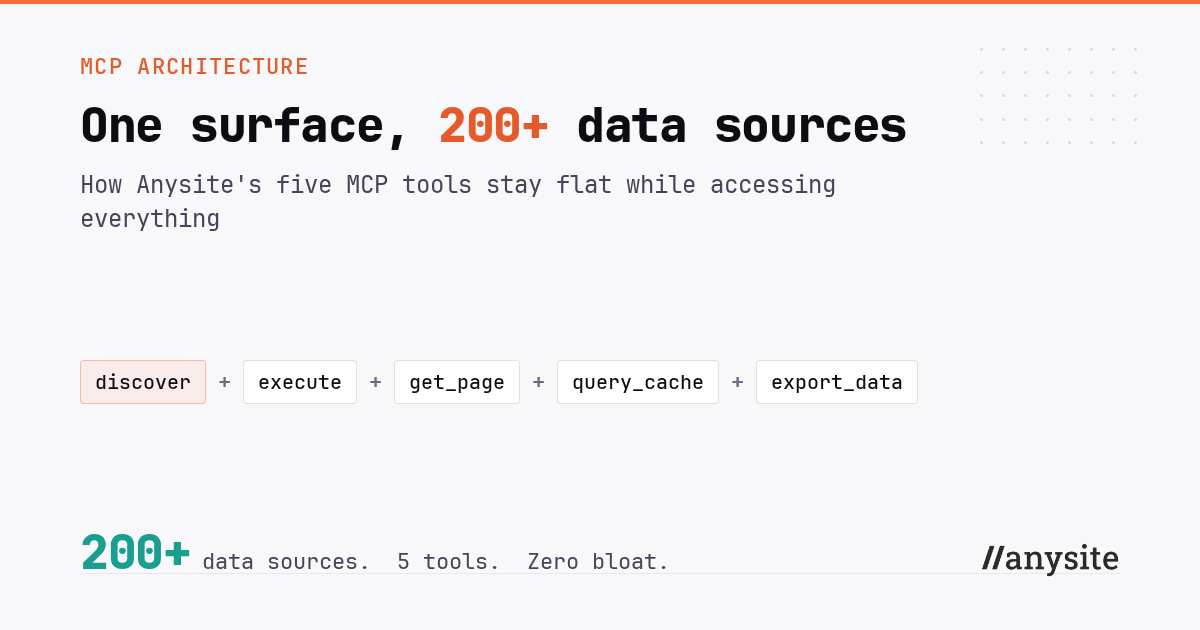
Anysite's version: five meta-tools and runtime introspection
Anysite reached the same conclusion in a refactor that shipped on 2026-03-17, and built the whole surface around it. Instead of one tool per endpoint, the entire catalog sits behind exactly five meta-tools:
discover(source, category)— enumerate the endpoints a source offers and the parameters each one accepts. You call this beforeexecute, because endpoint names and parameters are not meant to be guessed.execute(source, category, endpoint, params)— fetch data. It returns the first page of results plus acache_key.get_page(cache_key, offset, limit)— page through a result set you already fetched. Data stays cached for seven days, so continuing costs no new API credits.query_cache(cache_key, ...)— filter, sort, count, or aggregate already-fetched data without calling the source again.export_data(cache_key, format)— save the full dataset as JSON, CSV, or JSONL and get a download URL.
The shift is from compile-time schema to runtime introspection. Source and endpoint names are not baked into the tool definitions the model sees at boot. An agent that needs LinkedIn data calls discover("linkedin") to learn what is available — user, search, posts, and so on — then calls execute("linkedin", category, endpoint, params) with the parameters discover just described. The agent learns the small part of the API it needs, when it needs it, instead of carrying the entire catalog from the first token.
The proof point: the surface stayed flat
Here is the part that makes the design worth writing about. When this interface shipped in March 2026, it fronted roughly 40 sources. As of today (2026-06-22), the live reference at docs.anysite.io/llms-full.txt lists more than 1,300 endpoints across 200-plus sources — from LinkedIn, Instagram, TikTok, and YouTube to Amazon, Mercari, and Vinted; from Kalshi and Polymarket to arXiv and Semantic Scholar; plus official company registries across dozens of jurisdictions, from the UK's Companies House to Germany's Handelsregister and more than two dozen US state registries.
The catalog grew roughly five-fold in sources — from about 40 to 200-plus — and many times over in endpoints. The tool surface did not move. It was five tools then and it is five tools now. A model connecting to Anysite today sees the same five definitions it would have seen in March — a few hundred tokens — regardless of whether the catalog holds 40 sources or 200-plus. That is the whole argument in one sentence: scaling the catalog does not scale the tool surface. New sources land behind discover/execute and become reachable without adding a single tool definition to anyone's context window.
The tradeoffs, named honestly
This design is not free, and it is worth being precise about what it costs.
There is a mandatory discover round-trip. Before an agent can call a source it has not seen this session, it has to discover that source first. An agent that hits one source repeatedly amortizes this immediately. An agent that fans out across many sources pays one extra hop per new source before it gets useful data. For broad, shallow workloads that latency is real.
Parameter validation moves from schema to runtime. With a conventional tool list, the schema enumerates valid parameters, and a malformed call can be caught before it is sent. With a universal surface, the visible schema is just {source, category, endpoint, params}. The model can produce a structurally valid call that names an endpoint string that does not exist, and the error only surfaces after the server dispatches it. In practice this is contained by enforcing discover before execute — the discovery step is what tells the model the real endpoint names — but that discipline has to be in the agent's prompt, not the schema.
These are the right tradeoffs for a hosted catalog that grows every week, but they are tradeoffs, not free wins.
Why it matters
Tool-overload is a structural problem with MCP at scale, and the fix is the same wherever you look: discover on demand instead of loading everything upfront. Anysite applied that fix to one specific, fast-moving surface — a data catalog that has grown past 1,300 endpoints while the thing an agent connects to has stayed exactly five tools wide. If you are building an agent that needs data from many sources, that is the property worth borrowing: let the catalog grow, and keep the surface flat.
The full, current source-and-endpoint reference lives at docs.anysite.io/llms-full.txt.